
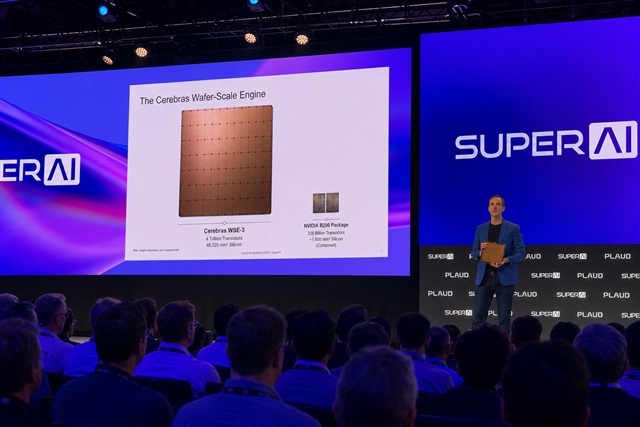
Andy Hock, chief strategy officer at Cerebras Systems, walked onto the Main Stage at SuperAI Singapore 2026 on Wednesday carrying the company's Wafer Scale Engine — the physical chip itself — and held it up for an audience of 10,000 before placing it next to...
The article requires paid subscription.
Subscribe Now