Samsung Electronics has backed AI chip design startup Normal Computing in a US$50 million funding round, expanding its push into AI-driven electronic design automation and next-generation...
Innodisk told attendees at the 2026 AI EXPO that effective AI deployment requires more than raw computing power; it depends on tight integration between software and hardware, and...
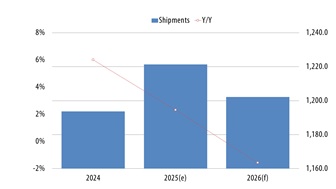
Amid the rapid development of generative artificial intelligence (GenAI) and large language models (LLM), global demand for high-performance computing (HPC) continues to rise. Memory...
MediaTek highlighted at AI EXPO Taiwan 2026 how language-specific challenges complicate the deployment of AI globally, as Taiwanese tonal variety, mixed writing systems, and local...
During the 2026 World Economic Forum (WEF), Nvidia CEO Jensen Huang made an impassioned case for digital sovereignty. "Build your own AI, take advantage of your fundamental natural...
A core researcher behind Alibaba's Qwen large language model has left the company and is reportedly joining ByteDance's AI research unit Seed, Chinese media reported. The move underscores...
Amazon Web Services (AWS) and AI chip startup Cerebras Systems said they are working together to bring a high-speed AI inference architecture to Amazon Bedrock, a managed service for...
The rapid expansion of generative artificial intelligence (AI) and large language models (LLMs) is driving a new phase of transformation in data center memory architecture, according...
Nvidia plans to shift the AI compute battleground from training to inference by integrating language processing unit technology and offering multiple inference chips, with OpenAI agreeing...
Alibaba Group Holding Ltd.'s core team behind its Qwen large language model faced renewed turbulence after the abrupt resignation of its original technical lead prompted an emergency...
Alibaba's large language model ambitions have been jolted by an unexpected leadership departure. In the early hours of March 4, the head of Alibaba Group's Qwen artificial intelligence...
As demand for computing power from AI large language models (LLMs) continues to surge, power density in data centers is rising in tandem, bringing the conversion losses of traditional...
Toronto-based AI chip startup Taalas says it can hardwire a large language model directly into silicon to accelerate inference beyond what conventional GPUs can deliver. Founded in...